JS原生操作DOM节点
JS原生操作DOM节点
创建、添加新节点
createDocumentFragment() 当需要多次appendChild时,可以先append到fragment页面片中,再一次性将该页面片append到DOM中,减少DOM渲染次数。
createElement(tagName)
createTextNode(text)
appendChild(ele)
insertBefor(ele)
删除、替换节点
removeChild(ele)
replaceChild()
查找节点
getElementsByTagName()
getElementsByClassName()
getElementById()
querySelector(CSS selectors):匹配指定 CSS 选择器的第一个元素。 如果没有找到,返回 null。
querySelectorAll():找出全部符合指定 CSS 选择器的元素。
getElement 与 querySelector 的区别
getElementsByTagName('a') 方法的性能通常比 querySelector('a') 要高很多。因为getElementsByTagName('a') 方法返回的是动态的NodeList,而 querySelector('a') 返回的是静态的NodeList.
getElementsByTagName() 方法返回对应标签名的元素的一个动态集合,只要document中相关元素发生变化,就会自动更新对应的元素。如果先获取了某个元素的子元素的动态集合 NodeList 对象,然后又在其他地方顺序添加更多子元素到这个DOM父元素中(可以是添加,修改,删除子元素等操作),这些更改将自动反射到 NodeList,不需要手动进行其他调用。下面的代码是个死循环:
|
|
querySelector()返回的 NodeList 就是方法被调用时刻的文档状态的快照。下面的代码就不会是个死循环:
|
|
Q:为什么返回动态的 NodeList 会更快?
A:因为返回静态的 NodeList 前要进行一系列的前期处理工作,而返回动态的 NodeList 则不需要。(涉及WebKit内核源码)。
关于两者的区别,在2017阿里校招笔试题中有涉及:整理在我的github上了。但是具体原因还没弄明白。
NaN, null, undefined的区别
null是一个表示”无”的对象,转为数值时为0
undefined是一个表示”无”的原始值,转为数值时为NaN
|
|
document.write 和 innerHTML
document.write 只能同步执行,如果在window.onload 之前执行则在文档流中绘制内容,如果在window.onload 之后则会重绘整个页面(之前内容被冲刷掉)
innerHTML 则是绘制某个元素内的内容,没有这个限制
内存泄漏
setTimeout第一个参数为字符串时造成内存泄漏的情况分析:
|
|
执行代码后,打开控制台,分别输入函数名test1和test2:
|
|
会发现,当第一个参数为函数时,回调函数执行完毕后,test1函数被销毁,其所使用内存也被释放;当第一个参数为字符串时,test2却始终存在,它没有被销毁,始终占据着内存,也就造成了内存泄漏。
所以让我们需要使用 setTimeout 时,一定要注意,第一个参数必须传入一个函数。
data-属性的作用
data-为H5新增的为前端开发者提供自定义的属性,这些属性集可以通过对象的 dataset 属性获取,不支持该属性的浏览器可以通过 getAttribute 方法获取 :
需要注意的是:data-之后的以连字符分割的多个单词组成的属性,获取的时候使用驼峰风格。 所有主流浏览器都支持 data-* 属性。
即:当没有合适的属性和元素时,自定义的 data 属性是能够存储页面或 App 的私有的自定义数据。
深拷贝
深复制和浅复制只针对像 Object, Array 这样的复杂对象的。简单来说,浅复制只复制一层对象的属性,而深复制则递归复制了所有层级。
|
|
数组去重
方法一:for循环中每次从原数组中取出一个元素,看这个元素是否已出现在结果数组中,注意NaN和{}
效率最低。
|
|
考虑 NaN和{}
|
|
修改后的数组去重:
|
|
方法二:遍历数组,利用indexOf判断元素下标是否为第一次出现的位置
|
|
方法三:用另一个对象存储出现过的元素
|
|
方法四:先排序。检查原数组中的第i个元素 与 结果数组中的当前最后一个元素是否相同,因为已经排序,所以重复元素会在相邻位置。
结果是排序后的,会打乱数组的原有顺序,看清题目要求
|
|
方法五:利用Set
|
|
函数节流throttle与函数防抖debounce
函数节流
《JavaScript高级程序设计》P614 Chap - 22.3.3:
“某些代码不可以在没有间断的情况连续重复执行。”
“只有在执行函数的请求停止了一段时间之后才执行。”
基本模式
|
|
throttle函数
红宝书的实现(我这里把延迟执行的时间修改成参数了):
|
|
其实还可以优化一下:实现可传参给实际执行的函数。
函数节流(throttle)与函数去抖(debounce)
这两个函数其实很类似,都是高阶函数,为了解决的问题也是一样的。
注意代码的封装(头条面试时,二面面试官给我的建议~)。
字符串截取函数比较
| 函数 | start | end | 备注 |
|---|---|---|---|
| substring | 必需,较小 | 较大,不包含,可选,若省略则到末尾 | 不接受负参数 |
| slice | 必需,若负则倒数 | 可选,若省略则到末尾,若负则倒数 | |
| substr | 必需,若负则倒数 | 可选,截取长度 | ECMAscript 没有对substr进行标准化,因此反对使用它。 |
splice()详解
arrayObject.splice(index,howmany,item1,.....,itemX)
splice()方法可删除从 index 处开始的零个或多个元素,并且用参数列表中声明的一个或多个值来替换那些被删除的元素。
如果从 arrayObject 中删除了元素,则返回的是含有被删除的元素的数组。
| Col1 | Col2 |
|---|---|
| index | 必需。整数,规定添加/删除项目的位置,使用负数可从数组结尾处规定位置。 |
| howmany | 必需。要删除的项目数量。如果设置为 0,则不会删除项目。 |
| item1, …, itemX | 可选。向数组添加的新项目。 |
多个标签页的通信
- localStorage,绑定事件监听其变化。
- cookie +
setInterval,定期查看cookies的值。
src和href的区别
- 可替换的元素上使用
src,然而把href用于在涉及的文档和外部资源之间建立一个关系。href(Hypertext Reference)指定网络资源的位置,从而在当前元素或者当前文档和由当前属性定义的需要的锚点或资源之间定义一个链接或者关系。src(Source)属性仅仅 嵌入当前资源到当前文档元素定义的位置。指向的内容将会嵌入到文档中当前标签所在位置;在请求src资源时会将其指向的资源下载并应用到文档内,例如 js 脚本,img图片和frame等元素。 src面对的是相对路径,href可以指向相对或者是绝对路径,url是服务器或者文件的路径,也有绝对和相对之分。
GET和POST的区别
等幂性
GET幂等:多次请求返回的资源不会变化。这只是一种标准。更实际的区别在于净荷的大小:浏览器和服务器会限制URL的长度。
POST非幂等,每次调用都会产生新的资源。不会限制发送给服务器的净荷的大小。
等幂性简单点说就是一次请求和多次请求,资源的状态是一样。比如GET和HEAD,不论你请求多少次,资源还是在那里。请注意,DELETE和PUT也是等幂的,以为对同一个资源删除一次或者多次,结果是一样的,就是资源被删除了,不存在了。
为什么说PUT也是等幂的?当你PUT一个新资源的时候,资源被创建,再次PUT这个URI的时候,资源还是没变。当你PUT一个存在的资源时,更新了资源,再次PUT的时候,还是更新成这个样子。在PUT更新的时候,不能做相对的更新(依赖资源现在的状态),比如每次对一个数加1,这样资源状态就会变化。应该每次更新成某个数,比如把某个数变成4,则无论多少次PUT,值都是4,这样就是等幂了。
我们设计Restful API的时候,GET,HEAD, PUT, DELETE一定要设计成等幂的。由于网络是不可靠的,安全性和等幂性就显得特别重要。如果一次请求,服务器收到处理以后,客户端没有收到相应,客户端会再次请求,如果没有等幂性保障,就会发生意想不到的问题。
POST是不安全也不等幂的,还是拿weblog的例子,如果两次POST相同的博文,则会产生两个资源,URI可能是这样/weblogs/myweblog/entries/1和/weblogs/myweblog/entries/2,尽管他们的内容是一样的。
其他方面
GET一般用于从服务端读取数据,POST一般用于发送数据到服务端。GET传送的数据GET比POST更安全。GET发送的参数或数据直接放在URL中,POST将数据放在HTTP请求头header中传递。GET有数据大小限制(因为URL有大小限制,一般2K),POST可传送更多的数据。
判断一个对象是否为数组
typeof(arr) 返回的是 Object
instanceof 在跨 frame 对象构建的场景下会失效
arr.toString() 返回的是数组的内容
一般用以下方法判断:
Array.isArray(obj);
Object.prototype.toString.call(obj) === '[object Array]';
字符串和数字类型隐式转换
|
|
字符串转数值
parseInt,parseFloatNumber()
HTTP头的缓存相关字段
Expires、Cache-Control、Last-Modified、 ETag是RFC 2616(HTTP/1.1)协议中和网页缓存相关的几个字段。
前两个用来控制缓存的失效日期,后两个用来验证网页的有效性。
Expires/Cache-Control
- 当客户端第一次访问资源的时候,服务端返回资源同时返回Expires(值为日期),在这个日期之前都不再向服务器请求该资源,而是到浏览器自己的缓存中读取。
- 为了避免用户自己修改本地机器的时间导致超过Expires而再次去服务器请求资源,设置Cache-Control(值为秒数)比Expires更合理。
- 如果Expires和Cache-Control同时存在,以后者为准。
Last-Modified/If-Modified-since(不考虑上述参数)
- 条件请求:如果服务器有个文件可能时不时会更新,客户端会时不时过来问一下浏览器缓存的文件是否过期,如果没过期,服务器不返回数据,只告诉客户端缓存还可以用(304)。
- 客户端第一次访问资源的时候,服务端返回资源的同时返回了Last-Modified;
- 浏览器缓存该资源的同时记录该日期,下次再请求资源的时候会带上If-Modify-since(值为Last-Modified这个日期)。如果服务器在这个日期之后没有修改过该资源,则返回304,否则返回200和修改后的资源。
ETag/If-None-Match
- 是另一种条件请求的实现方式
- 第一次请求资源返回资源和Etag标签,下次请求资源要带上If-None-Match(值为资源的ETag),服务器比较ETag和传来的If-None-Match,如果不一样就200,一样就304。
- ETag实际上很少人使用,因为它的计算是使用算法来得出的,而算法会占用服务端计算的资源,所有服务端的资源都是宝贵的。
关于刷新
- 浏览器中写地址,回车:有缓存就不发请求直接读缓存。
- F5刷新:即使有缓存也要带上If-Modified-since去问服务器有没有更新。
- Ctrl+F5: 强行更新,把缓存删了,重新请求。
JavaScript语法优化
- 避免全局查找:缓存到局部变量
- 重复使用的调用结果先保存到局部变量
- 定时器:多次定时启动要用
setInterval - 字符串连接:多次对同一个字符串进行
+=操作的话,最好使用一个缓存,使用JavaScript数组来收集,最后使用join方法连接起来 - 避免with语句:会增长作用域链
- 数字转换成字符串:
"" + 1效率较高。("" +) >String()>.toString()>new String() - 浮点数转换成整型:
Math.floor()或者Math.round() - 多个类型声明:组合起来用一个var声明
- 插入迭代器:
var name=values[i++] - 使用直接量定义变量:
|
|
- 使用
document.createDocumentFragment优化多次appendChild - 使用一次
innerHTML赋值代替构建DOM元素:node.cloneNode(deep)克隆节点及其后代;deep可选,默认是false,设置为true– 还会克隆节点属性。 - 通过模板元素
clone代替createElement - 使用
firstChild和nextSibling代替childNodes遍历DOM元素 - 删除DOM节点时要删除节点的绑定事件,且用
innerHTML=""比removeChild效率更高 - 使用事件代理
- 最小化对
NodeList的访问次数。这些地方会返回NodeList:对getElementsByTagName()的调用,获取了元素的childNodes属性,获取了元素的attributes属性,访问了特殊的集合,如document.forms、document.images等等。 - 优化循环:减值迭代,简化终止条件的计算,简化循环体,使用后测试循环do-while(效率:
while>for(;;)>for(in)); - 避免双重解释:少用eval;不要给setInterval和setTimeout使用字符串表示的函数语句传递函数参数;
- 缩短否定检测
- 条件分支:按可能性从高到低排序,缩短解释器对条件的探测次数;多分支情况要考虑用效率更高的switch而不是if-else;使用三目运算符代替条件分支
- 使用常量:任何在多处用到的值;URL;任意可能会改的值
- 避免与
null进行比较,用以下方法代替:用instanceof检测引用类型;用typeof检测基本类型;检测对象是否包含某个特定的方法,用typeof检测; - 注意全局变量的使用:如果只用一次而不需要再次引用,用IIFE;如果外面还需要再次引用,用命名空间:
|
|
- 尊重对象的所有权:不要重复定义其他团队定义过的方法,不要修改不是自己定义的对象;创建自定义类,继承某类,再添加新功能。
- 避免循环引用
- IE下通过js创建的DOM对象必须
append到页面中,不然,刷新页面这部分内存也不会回收 - 使用
innerHTML置空来释放某元素下的子元素的内存 - 释放js对象:
obj=null; delete obj.prop; splice删除数组中不需要的元素; - 避免String的隐式装箱:如果要用到String的方法,应先将字符串转成一个String对象
- 解耦:HTML/js ;CSS/js :
element.style.color可改为element.className="color";事件处理程序和应用逻辑:一个事件处理程序应该从事件对象中提取,并将这些信息传送给处理应用逻辑的某个方法中。 - 位运算较快
- 巧用||和&&
|
|
- if语句即使只有一句也要用
{}; - 谨慎使用
+号
|
|
- 使用
return注意: 一条有返回值的return语句不要用()括号来括住返回值;如果返回表达式,则表达式应与return关键字在同一行 - 最好用
===/!===,因为==/!=会进行强制类型转换 - 函数最好返回统一类型
- 总是检车用户输入的数据的类型
- 部署:JSLint检测语法;使用压缩工具压缩js;文件编码统一用UTF-8
如何区别浏览器和版本
|
|
获取浏览器高度和宽度
|
|
求出当前日期内月份的天数
|
|
函数声明和函数表达式的区别
- 函数声明:可以先调用,再声明,因为会函数声明在JS解析时进行函数提升。
- 函数表达式:函数表达式的值是在JS运行时确定,并且在表达式赋值完成后,该函数才能调用。
HTML语义化
header, footer,hgroup, nav, aside, section, section, article,
header, footer可以用于网页,或者section中。
article中嵌套article:文章article嵌套评论article;
article中嵌套section:section是并列的,共同组成文章整体的某几个部分、章节;
section中嵌套article:section将各个整体article包裹起来形成团体。
有利于浏览器爬虫解析,SEO;页面结构优雅。
arguments转数组
将类数组(Array-Like)对象arguments转换成数组可以采用以下的方法:
Array.apply(null,arguments);
Array.prototype.slice.call(arguments,0);
Array.prototype.splice.call(arguments,0,arguments.length);
严格模式的限制(了解)
- 变量必须声明后再使用
- 函数的参数不能有同名属性,否则报错
- 不能使用
with语句 - 不能对只读属性赋值,否则报错
- 不能使用前缀0表示八进制数,否则报错
- 不能删除不可删除的属性,否则报错
- 不能删除变量
delete prop,会报错,只能删除属性delete global[prop] eval不会在它的外层作用域引入变量eval和arguments不能被重新赋值arguments不会自动反映函数参数的变化- 不能使用
arguments.callee - 不能使用
arguments.caller - 禁止
this指向全局对象,顶层的this指向undefined - 不能使用
fn.caller和fn.arguments获取函数调用的堆栈 - 增加了保留字(比如
protected、static和interface)
jQuery相关
.prop .attr
底层实现不同
attr主要依赖setAttribute()和getAttribute()
getAttribute方法有个潜规则:部分特殊属性(比如input的value和checked), getAttribute取到的是初始值
prop主要依赖原生对象属性获取和设置方式:element[property]
操作对象不同
attr设置/获取指定DOM元素对应的文档节点上的属性
prop设置/获取指定DOM元素(是个js对象)上的属性
用于设置的属性值的类型不同
attr 只能是字符串类型,如果不是则会调用toString将其转换为字符串类型
prop 可以是包括数组和对象在内的任意类型
注意
DOM元素某些属性的更改也会影响到元素节点上对应的属性。例如:property 的id对应 attribute 的id,property的 className 对应 attribute 的class。
对于a标签的href属性,prop()与attr()取得的值不同:prop是绝对地址,attr的就是href中的值
.data()
- 在html5中DOM标签可以添加一些
data-xxx的属性 data()存取的内容可以是字符串、数组和对象data()设置值后,attr()不能获取设置后的值,只能通过.data()获取- 性能对比:
.prop()>.data()>.attr()
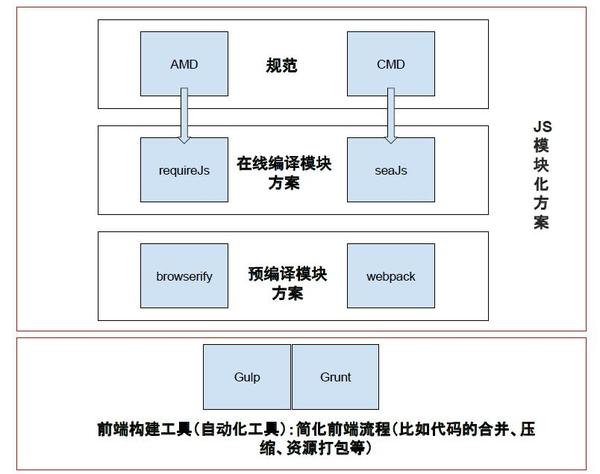
Webpack VS Grunt/Gulp
HTTPS如何保证安全
不安全:中间路由截取嗅探、冒充篡改 -> 对称加密 -> 对称加密用的key的传输仍可能被截取而解密 -> 引入非对称加密传输对称加密所需的key -> 仍有可能中间人冒充,用假的公钥 -> 引入CA,将公钥放在数字证书中
对称加密AES + 非对称加密RSA + CA证书
SSL/TLS协议:公钥可以自由传播,无需担心系统安全性降低;但私钥应妥善保管,不可将其泄露给未经授权解密的信息的用户,这就是“公钥”和“私钥”这两个名称的由来。
公钥加密计算量太大,如何减少耗用的时间?
解决方法:每一次对话(session),客户端和服务器端都生成一个”对话密钥”(session key),用它来加密信息。由于”对话密钥”是对称加密,所以运算速度非常快,而服务器公钥只用于加密“对话密钥”本身,这样就减少了加密运算的消耗时间。
SSL/TLS协议的基本过程是这样的:
(1) 客户端向服务器端索要并验证公钥。
(2) 双方协商生成”对话密钥”。
(3) 双方采用”对话密钥”进行加密通信。
TCP相关问题
TCP如何保证可靠传输
(0)应用数据被分割成TCP认为最适合发送的数据块。这和UDP完全不同,应用程序产生的数据报长度将保持不变。
(1)当TCP发出一个报文段后,就启动一个定时器,用来等待目的端确认收到这个报文段;若没能及时收到这个确认,TCP发送端将重新发送这个报文段(超时重传);
(2)TCP收到一个发自TCP连接的另一端的数据后就将发送一个确认,不过这个确认不是立即就发送,而是要推迟几分之一秒后才发送;
(3)TCP将保持它的首部和数据的检验和;(这是一个端到端的检验和,为了检验数据在传输过程中发生的错误;若检测到段的检验和有差错,TCP将丢弃和不确认收到此报文段并希望发端可以进行超时重传);
(4)由于TCP报文段是作为IP数据报来传输的,又因为IP数据报的到达可能会失序,所以TCP报文段的到达也可能会失序;因此,有必要的话TCP会对收到的数据进行重新排序后交给应用层;
(5)因为TCP报文段是作为IP数据报来传输的,并且IP数据报可能会发生重复,所以TCP的接收端必须丢弃掉重复的数据;
(6)TCP提供流量控制;(因为TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据,这一限制可以防止较快主机致使较慢主机的缓冲区溢出)。
TCP协议作为一个可靠的面向流的传输协议,其可靠性和流量控制由滑动窗口协议保证,而拥塞控制则由控制窗口结合一系列的控制算法实现。
TCP滑动窗口协议
发送方窗口:发送方窗口内的序列号代表了那些已经被发送,但是还没有被确认的帧,或者是那些可以被发送的帧。
接收方窗口:连续的允许接收的帧的序号
三种协议:窗口大小不同
1比特滑动窗口协议(停等协议):发送窗口=1,接收窗口=1。发送方每发送一帧后就要停下来,等待接收方已正确接收的确认返回后才能继续发送下一帧。
后退N协议:发送方在发完一个数据帧后,不停下来等待应答帧,而是连续发送若干个数据帧,即使在连续发送过程中收到了接收方发来的应答帧,也可以继续发送。且发送方在每发送完一个数据帧时都要设置超时定时器。只要在所设置的超时时间内仍未收到确认帧,就要重发相应的数据帧。如:当发送方发送了N个帧后,若发现该N帧的前一个帧在计时器超时后仍未返回其确认信息,则该帧被判为出错或丢失,此时发送方就不得不重新发送出错帧及其后的N帧。
选择重传协议:当接收方发现某帧出错后,其后继续送来的正确的帧虽然不能立即递交给接收方的高层,但接收方仍可收下来,存放在一个缓冲区中,同时要求发送方重新传送出错的那一帧。一旦收到重新传来的帧后,就可以原已存于缓冲区中的其余帧一并按正确的顺序递交高层。选择重发减少了浪费,但要求接收方有足够大的缓冲区空间。
TCP和UDP的区别
[1] 基于连接与无连接:UDP无连接,TCP面向连接;
[2] UDP相对于TCP更快,额外开销较小,程序结构较简单;
[3] UDP尽最大努力交付,不保证可靠,TCP可靠;
[4] 对系统资源的要求:TCP较多,UDP少;
[5] TCP流模式,UDP数据报模式;区别
[6] TCP保证数据正确性,UDP可能丢包;TCP保证数据顺序,UDP不保证。
Ping命令的原理是发送UDP数据包。
三次握手
TCP是面向连接的可靠的运输层通信协议。完成三次握手后,TCP连接建立,可以传输数据。
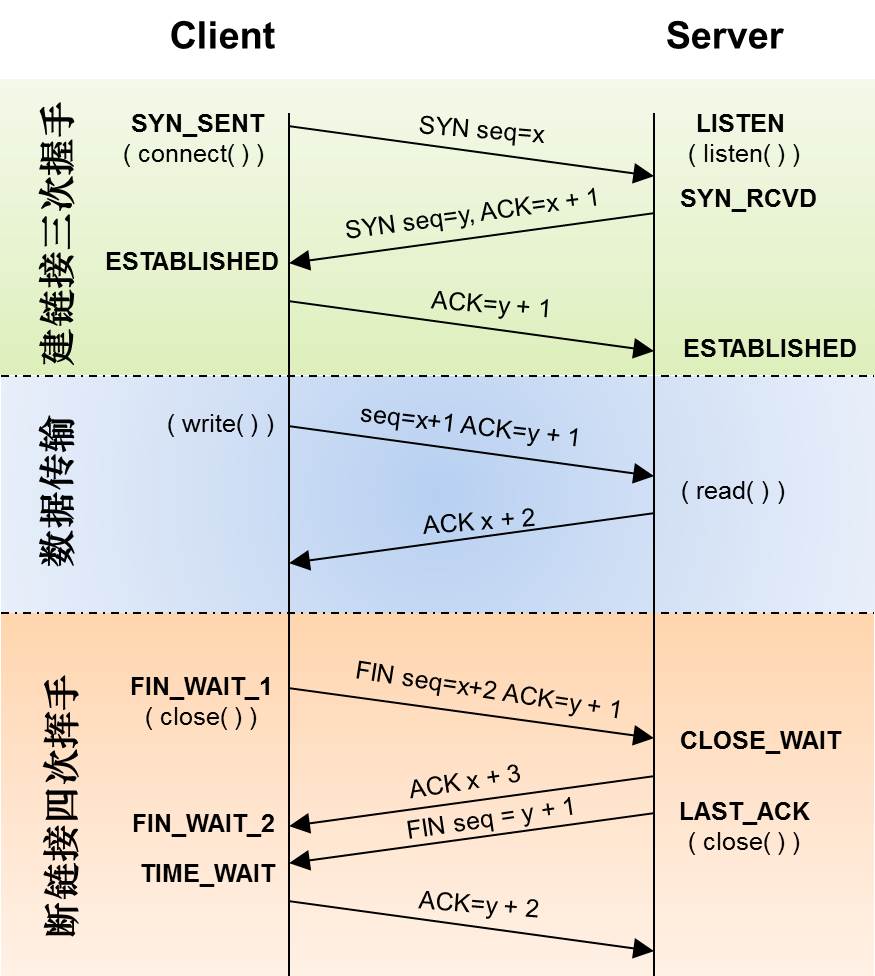
为什么两次不够,需要三次:为了防止已失效的连接请求报文段突然又传送到了服务端,防止了服务器端的一直等待而浪费资源,产生错误。
看一段代码
|
|
setTimeout 和 setInterval 的区别
涉及到JS执行线程和代码执行队列的问题。
JavaScript都是以单线程的方式运行于浏览器的JavaScript引擎中的, setTimeout和setInterval的作用只是把你要执行的代码在你设定的一个时间点插入js引擎维护的一个代码队列中, 插入代码队列并不意味着你的代码就会立马执行。
定时器的回调函数并不是相当于在时间到了就执行,而是有一个主js执行进程,这个进程是页面刚加载的时候页面按照加载顺序执行的js代码,此外还有一个需要在进程空闲的时候执行的代码队列,而我们所说的定时器的回调就是相当于在delay之后把定时器回调放入到空闲队列中(注意,空闲队列有可能还有其它的代码,比如点击事件,因此定时器回调放入的位置不一定是空闲队列的开始位置)
setTimeout
|
|
如果block2的代码执行时间超过200ms:在block2执行过程中(执行了200ms后)process代码被插入代码队列, 但一直要等click方法执行结束, 才会执行process代码段。
如果block2代码执行的时间<200ms: setTimeout在200ms后将process代码插入到代码队列, 而那时执行线程可能已经处于空闲状态了(idle), 那结果就是200ms后, process代码插入队列就立马执行了, 就让你感觉200ms后, 就执行了.
setInterval
只要一次计时完毕,插入回调之后不管回调执不执行就开始计时。当我们插入回调的时候前队列有别的代码在执行,这时候回调肯定是不会执行的,因此如果这个时候无限定时时间到了会再次插入回调,这个时候如果发现队列中的第一次回调没有执行,那么再次插入的回调浏览器就默认取消。==> 有时不想这样让他自动取消掉我们的回调函数,所以有更好的办法:用setTimout代替setInterval。(有时候面试官会这么问:怎么让setTimeout像setInverval一样执行?)
|
|
document.getElementsByClassName的兼容性问题
对IE来说,IE9及其以上才支持。
我的github - waterfallLayout项目中有写原生实现getElementsByClassName(针对className只有一个样式)。
window.onload=function(){} 和 $(document).ready(function{})的区别
- 执行时间
window.onload必须等到页面内包括图片的所有元素加载完毕后才能执行。
$(document).ready()是DOM结构绘制完毕后就执行,不必等到加载完毕。
jQuery中等价于window.onload = function(){}的写法是$(window).load(function(){}).
- 编写个数不同
window.onload不能同时编写多个,如果有多个window.onload方法,只会执行最后一个。
$(document).ready()可以同时编写多个,并且都可以得到执行(按照编写顺序执行)。
- 简化写法
window.onload没有简化写法
$(document).ready(function(){})可以简写成$(function(){});
如果src=''会怎样
yahoo 网页性能优化准则之一:避免空的src
img的src为空或者#,都会发一次请求,浏览器会用当前路径发起一次请求。
空的图片src仍然会使浏览器发送请求到服务器,这样完全是浪费时间,而且浪费服务器的资源。尤其是你的网站每天被很多人访问的时候,这种空请求造成的伤害不容忽略。空的src被定义为当前页面。